











スパコン富岳で大規模言語モデル 高い日本語能力、一般に公開
共同通信
東京工業大や理化学研究所、富士通などのチームは10日、スーパーコンピューター「富岳」を活用し、日本語能力に優れた生成AIの基盤技術「大規模言語モデル」を独自に開発したと発表した。企業や大学がダウンロードして使用できるほか、一般市民も富士通のホームページから試すことができる。
大規模言語モデルは欧米や中国だけでなく、日本でも大学や企業が開発を進めている。今回は富岳を含めて国産の技術を活用し、学習に使う日本語のデータも独自にまとめた。
チームはインターネット上の文章を蓄積するデータベースから質の高い日本語の文章を選別。富岳を使ってAIの学習を進め、1年弱で完成した。敬語や日本文化を背景とした会話を自然にこなせるのが特徴だという。
生成AIの開発にはGPUと呼ばれる半導体が適しているが、米エヌビディアなど海外企業がシェアの大半を占め、世界的な需要に追い付いていない。富岳はGPUを使っておらず、チームは今回CPUによる計算速度を6倍に高め、国産スパコンでも生成AIが開発できることを示した。
RECOMMEND
あなたにおすすめ
Recommend by Aritsugi Lab.
PICK UP
注目コンテンツ





NEWS LIST
全国のニュース 「科学・環境」記事一覧-
玄海原発で点検遅れ 非常用発電機の動作確認
共同通信
-
北日本「海洋熱波」で昨夏猛暑に 雲少なく日射増、英科学誌発表
共同通信
-
老化卵子の染色体異常解明、理研 マウス実験、流産メカニズム理解
共同通信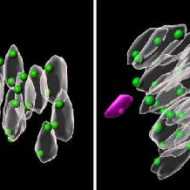
-
原発の処理水放出「基準に適合」 IAEA、2回目報告書
共同通信
-
女川原発、再稼働11月に延期 東北電力、仮設倉庫の撤去遅れ
共同通信
-
帯状疱疹、65歳に定期接種 厚労省部会、ワクチン支援で案
共同通信
-
コスモス国際賞に英博士 生物保全科学の先駆者
共同通信
-
JR東海社長、水位低下で釈明 「原因究明考えた」、リニア工事
共同通信
-
規制委、東電と意見交換 デブリ取り出し安全確保で
共同通信
-
知床基地局を整備する影響照会 ユネスコ、日本政府に
共同通信



